2025A-TLV编码
题目描述与示例
题目
TLV 编码是按 TagLengthValue 格式进行编码的。
一段码流中的信元用 tag 标识,tag 在码流中唯一不重复,length 表示信元 value 的长度,value 表示信元的值,码流以某信元的 tag 开头,tag固定占一个字节,length固定占两个字节,字节序为小端序。
现给定 TLV 格式编码的码流以及需要解码的信元 tag,请输出该信元的value。
输入码流的 16 进制字符中,不包括小写字母;且要求输出的 16 进制字符串中也不要包含小写字母;码流字符串的最大长度不超过 50000 个字节。
输入描述
第一行为第一个字符串 ,表示待解码信元的 tag;输入第二行为一个字符串, 表示待解码的 16 进制码流;字节之间用 空格 分割。
输出描述
输出一个字符串,表示待解码信元以 16 进制表示的 value。
示例
输入
31
32 01 00 AE 90 02 00 01 02 30 03 00 AB 32 31 31 02 00 32 33 33 01 00 CC输出
32 33说明
需要解析的信元的 tag 是 31;从码流的起始处开始匹配:
第一个信元的tag 为 32 ,其长度为 1(01 00,小端序表示为十六进制的0001,十进制为1),匹配接下来的1个字节AE;
第二个信元的 tag 为 90 其长度为 2(02 00,小端序表示为十六进制的0002,十进制为2,匹配接下来的2个字节01 02;
第三个信元的 tag 为 30 其长度为 3(03 00,小端序表示为十六进制的0003,十进制为3,匹配接下来的3个字节AB 32 31;
第四个信元的 tag 为 31 其长度为 2(02 00,小端序表示为十六进制的0002,十进制为2,匹配接下来的2个字节32 33;
所以返回长度后面的两个字节即可 为 32 33。
解题思路
又是一道比较难读懂的题目,需要一些前置知识的理解。
大端序和小端序
这道题涉及一个前置知识,大端序和小端序。
这两种排序都是字节序,表示的是数据字节在内存中存储方式。
大端序(Big-Endian)指的是数据的低位字节存放在内存的高位地址,高位字节存放在内存的低位地址。这种排列方式与数据用字节表示时的书写顺序一致,符合人类的阅读习惯。
小端序(Little-Endian)指的数据的低位字节存放在内存的低位地址,高位字节存放在高位地址。小端序与人类的阅读习惯相反,但更符合计算机读取内存的方式,因为CPU读取内存中的数据时,是从低地址向高地址方向进行读取的。
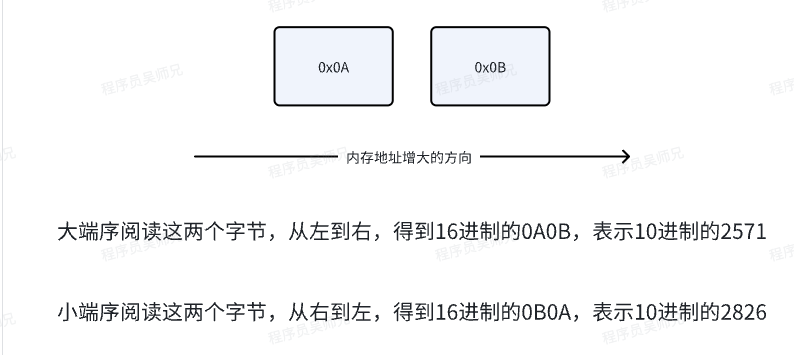
看起来有点拗口,但只需要记住大端序从左到右排列符合人类阅读习惯,小端序从右到左排列不符合人类阅读习惯即可。
TLV码流的解码过程
下图显示了示例的码流的解码过程
- 蓝绿红构成的一整段内容表示一个信元,其中
- 蓝色表示信元的唯一标识
tag - 绿色表示信元的
value的长度 - 红色表示信元的
value的的内容
- 蓝色表示信元的唯一标识
32 01 00 AE 90 02 00 01 02 30 03 00 AB 32 31 31 02 00 32 33 33 01 00 CC我们要做的事情,就是找到tag为所第一行输入的target_tag的那个信元,所对应的value的内容。
模拟过程
本题剩余内容,只需要按照题目要求进行模拟即可。
我们可以构建一个help辅助函数,用于一个特定信元的解码。
其中,传入的参数stream为输入码流数组,idx为当前信元标识在数组中的索引。容易得到代码
# 构建一个用于解码的辅助函数
def help(stream, idx):
cur_tag = stream[idx]
# 信元长度length为小端序排布,得到十六进制的字符串结果
cur_length_hex = stream[idx+2] + stream[idx+1]
# 将十六进制转换为十进制
cur_length = int(cur_length_hex, base = 16)
# 返回当前信元标识,信元内容的长度
return cur_tag, cur_length在这个函数外部,由于idx增加的幅度是根据每次解码后得到的信元内容的长度length决定的,并不是一个固定值,我们需要在while循环中进行遍历。
循环条件为,idx在stream中对应的字符串不是目标信元target_tag。
在循环中,我们调用help函数,得到当前信元的标识cur_tag和长度cur_length。
信元表示和长度一共占3位,信元中的信息占cur_length位,因此下一个信元的标识tag的位置位于stream数组中的idx + 3 + cur_length处。综上可以得到代码
# idx是stream流中的索引,初始化为0
idx = 0
# 进行循环,循环条件为idx对应的字符串不是目标信元target_tag
while stream[idx] != target_tag:
# 根据当前的idx,获得当前信元的tag和长度
cur_tag, cur_length = help(stream, idx)
# 信元和长度一共占3位,信元中的信息占cur_length位
# 下一个信元tag的位置位于 idx + 3 + cur_length 处
# 更新idx
idx += 3 + cur_length退出while循环后,idx所在的位置即为目标信元target_tag的标识。
再一次调用help函数,进行信元解码,得到目标信元的长度cur_length。
此时stream中,从索引idx+3到idx+3+cur_length位置的切片,就是目标信元的内容,将其输出即为最终的答案。
# 退出循环后再进行一次信元解码
# 此时得到的cur_tag一定是target_tag
cur_tag, cur_length = help(stream, idx)
# 此时stream中,从 idx+3 到 idx+3+cur_length 位置的切片
# 即为信元target_tag解码得到的字节
print(" ".join(stream[idx+3:idx+3+cur_length]))代码
Python
# 欢迎来到「欧弟算法 - 华为OD全攻略」,收录华为OD题库、面试指南、八股文与学员案例!
# 地址:https://www.odalgo.com
# 华为OD机试刷题网站:https://www.algomooc.com
# 添加微信 278166530 获取华为 OD 笔试真题题库和视频
# 构建一个用于解码的辅助函数
def help(stream, idx):
cur_tag = stream[idx]
# 信元长度length为小端序排布,得到十六进制的字符串结果
cur_length_hex = stream[idx+2] + stream[idx+1]
# 将十六进制转换为十进制
cur_length = int(cur_length_hex, base = 16)
return cur_tag, cur_length
# 待解码信元的tag
target_tag = input()
# 待解码的编码流
stream = input().split()
# idx是stream流中的索引,初始化为0
idx = 0
# 进行循环,循环条件为idx对应的字符串不是目标信元target_tag
while stream[idx] != target_tag:
# 根据当前的idx,获得当前信元的tag和长度
cur_tag, cur_length = help(stream, idx)
# 信元和长度一共占3位,信元中的信息占cur_length位
# 下一个信元tag的位置位于 idx + 3 + cur_length 处
# 更新idx
idx += 3 + cur_length
# 退出循环后再进行一次信元解码
# 此时得到的cur_tag一定是target_tag
cur_tag, cur_length = help(stream, idx)
# 此时stream中,从 idx+3 到 idx+3+cur_length 位置的切片
# 即为信元target_tag解码得到的字节
print(" ".join(stream[idx+3:idx+3+cur_length]))Java
import java.util.*;
public class Main {
// 构建一个用于解码的辅助函数
public static String[] decodeHelper(String[] stream, int idx) {
String curTag = stream[idx];
// 信元长度length为小端序排布,得到十六进制的字符串结果
String curLengthHex = stream[idx + 2] + stream[idx + 1];
// 将十六进制转换为十进制
int curLength = Integer.parseInt(curLengthHex, 16);
return new String[] { curTag, String.valueOf(curLength) };
}
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
// 待解码信元的tag
String targetTag = scanner.nextLine();
// 待解码的编码流
String[] stream = scanner.nextLine().split(" ");
// idx是stream流中的索引
int idx = 0;
// 进行循环,循环条件为idx对应的字符串不是目标信元targetTag
while (!stream[idx].equals(targetTag)) {
// 根据当前的idx,获得当前信元的tag和长度
String[] result = decodeHelper(stream, idx);
String curTag = result[0];
int curLength = Integer.parseInt(result[1]);
// 信元和长度一共占3位,信元中的信息占curLength位
// 下一个信元tag的位置位于 idx + 3 + curLength 处
idx += 3 + curLength;
}
// 退出循环后再进行一次信元解码
// 此时得到的curTag一定是targetTag
String[] result = decodeHelper(stream, idx);
String curTag = result[0];
int curLength = Integer.parseInt(result[1]);
// 输出信元的字节
System.out.println(String.join(" ", Arrays.copyOfRange(stream, idx + 3, idx + 3 + curLength)));
scanner.close();
}
}C++
#include <iostream>
#include <vector>
#include <sstream>
using namespace std;
// 构建一个用于解码的辅助函数
pair<string, int> decodeHelper(const vector<string>& stream, int idx) {
string cur_tag = stream[idx];
// 信元长度length为小端序排布,得到十六进制的字符串结果
string cur_length_hex = stream[idx + 2] + stream[idx + 1];
// 将十六进制转换为十进制
int cur_length = stoi(cur_length_hex, nullptr, 16);
return {cur_tag, cur_length};
}
int main() {
string target_tag;
getline(cin, target_tag);
string line;
getline(cin, line);
// 将输入的编码流分割并存入vector中
vector<string> stream;
stringstream ss(line);
string token;
while (ss >> token) {
stream.push_back(token);
}
// idx是stream流中的索引
int idx = 0;
// 进行循环,循环条件为idx对应的字符串不是目标信元target_tag
while (stream[idx] != target_tag) {
// 根据当前的idx,获得当前信元的tag和长度
auto [cur_tag, cur_length] = decodeHelper(stream, idx);
// 信元和长度一共占3位,信元中的信息占cur_length位
// 下一个信元tag的位置位于 idx + 3 + cur_length 处
idx += 3 + cur_length;
}
// 退出循环后再进行一次信元解码
// 此时得到的cur_tag一定是target_tag
auto [cur_tag, cur_length] = decodeHelper(stream, idx);
// 输出信元的字节
for (int i = idx + 3; i < idx + 3 + cur_length; ++i) {
cout << stream[i] << " ";
}
cout << endl;
return 0;
}C
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define MAX_STREAM_SIZE 50000 // 设定最大输入流大小
#define MAX_TAG_SIZE 10 // 设定最大Tag长度
// 构建一个用于解码的辅助函数
void decodeHelper(char **stream, int idx, char *curTag, int *curLength) {
strcpy(curTag, stream[idx]);
// 信元长度length为小端序排布,得到十六进制的字符串结果
char curLengthHex[5];
sprintf(curLengthHex, "%s%s", stream[idx + 2], stream[idx + 1]);
// 将十六进制转换为十进制
*curLength = (int)strtol(curLengthHex, NULL, 16);
}
int main() {
char targetTag[MAX_TAG_SIZE]; // 待解码信元的tag
char *stream[MAX_STREAM_SIZE]; // 待解码的编码流
char buffer[MAX_STREAM_SIZE * 5]; // 用于存储输入的字符串
int idx = 0;
// 读取目标信元的tag
scanf("%s", targetTag);
getchar(); // 读取换行符,防止干扰
// 读取编码流
fgets(buffer, sizeof(buffer), stdin);
// 解析输入流
char *token = strtok(buffer, " ");
int streamSize = 0;
while (token != NULL) {
stream[streamSize++] = token;
token = strtok(NULL, " ");
}
// 进行循环,循环条件为idx对应的字符串不是目标信元targetTag
while (strcmp(stream[idx], targetTag) != 0) {
char curTag[MAX_TAG_SIZE];
int curLength;
// 获取当前信元的tag和长度
decodeHelper(stream, idx, curTag, &curLength);
// 信元和长度一共占3位,信元中的信息占curLength位
// 下一个信元tag的位置位于 idx + 3 + curLength 处
idx += 3 + curLength;
}
// 退出循环后再进行一次信元解码
char curTag[MAX_TAG_SIZE];
int curLength;
decodeHelper(stream, idx, curTag, &curLength);
// 输出信元的字节
for (int i = idx + 3; i < idx + 3 + curLength; i++) {
printf("%s ", stream[i]);
}
printf("\n");
return 0;
}Node JavaScript
const readline = require('readline');
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout
});
// 解码辅助函数
function decodeHelper(stream, idx) {
let curTag = stream[idx];
// 信元长度为小端序,需要交换字节顺序
let curLengthHex = stream[idx + 2] + stream[idx + 1];
// 将十六进制字符串转换为十进制数
let curLength = parseInt(curLengthHex, 16);
return [curTag, curLength];
}
let inputLines = [];
rl.on('line', (line) => {
inputLines.push(line);
if (inputLines.length === 2) {
rl.close();
}
}).on('close', () => {
let targetTag = inputLines[0]; // 待解码信元的 tag
let stream = inputLines[1].split(" "); // 编码流
let idx = 0;
// 进行循环,直到找到目标信元
while (stream[idx] !== targetTag) {
let [curTag, curLength] = decodeHelper(stream, idx);
// 信元和长度信息占3字节,数据部分占 curLength 字节
idx += 3 + curLength;
}
// 退出循环后,解码目标信元
let [curTag, curLength] = decodeHelper(stream, idx);
// 输出信元的字节信息
console.log(stream.slice(idx + 3, idx + 3 + curLength).join(" "));
});Go
package main
import (
"bufio"
"fmt"
"os"
"strconv"
"strings"
)
// 构建一个用于解码的辅助函数
func decodeHelper(stream []string, idx int) (string, int) {
curTag := stream[idx]
// 信元长度length为小端序排布,得到十六进制的字符串结果
curLengthHex := stream[idx+2] + stream[idx+1]
// 将十六进制转换为十进制
curLength, _ := strconv.ParseInt(curLengthHex, 16, 64)
return curTag, int(curLength)
}
func main() {
reader := bufio.NewReader(os.Stdin)
// 读取目标信元的tag
targetTag, _ := reader.ReadString('\n')
targetTag = strings.TrimSpace(targetTag)
// 读取编码流
line, _ := reader.ReadString('\n')
stream := strings.Fields(line) // 按空格拆分字符串
idx := 0
// 进行循环,循环条件为idx对应的字符串不是目标信元targetTag
for stream[idx] != targetTag {
// 获取当前信元的tag和长度
_, curLength := decodeHelper(stream, idx)
// 信元和长度一共占3位,信元中的信息占curLength位
// 下一个信元tag的位置位于 idx + 3 + curLength 处
idx += 3 + curLength
}
// 退出循环后再进行一次信元解码
_, curLength := decodeHelper(stream, idx)
// 输出信元的字节
fmt.Println(strings.Join(stream[idx+3:idx+3+curLength], " "))
}时空复杂度
时间复杂度:O(N)。需要一次遍历码流数组stream。
空间复杂度:O(1)。进入若干长度变量